2026年4月24日,中国深度求索公司正式上线DeepSeek-V4系列模型并同步开源。 这一标志性事件不仅在百万级长上下文与复杂推理领域树立了新的行业标杆,更在底层基础设施层面释放出强烈的产业重构信号。结合宏观经济数据与行业发展态势,本文将从"去英伟达"进程、电力能耗约束以及Token定价的下半场演进三个维度,进行深度的逻辑推演与分析。
一、 算力底座重构:加速"去英伟达"化与国产替代
DeepSeek-V4的发布,实质上宣告了国产大模型在最顶尖的算力基础设施上已完成"脱钩断链"的压力测试。
1. 从CUDA向CANN的底层跨越
根据观察者网及凤凰网科技披露的官方信息,下一代旗舰模型DeepSeek-V4已完全运行于华为昇腾950PR芯片,其技术架构正式从英伟达CUDA全面转向华为CANN框架。 这一客观事实打破了海外大厂在高端AI算力生态上的绝对垄断,验证了全栈国产算力承载万亿参数模型的工程可行性。
2. 算力性能与市场格局重塑
在芯片性能指标上,华为于今年3月发布的Atlas 350加速卡(搭载昇腾950PR)单卡算力达到英伟达H20的2.87倍,且为目前国内唯一支持FP4推理的产品。
业内专家分析认为,随着寒武纪、海光信息等国产芯片企业进入规模化适配期,中国AI算力市场正迎来历史性拐点。据国际研究机构Bernstein Research预测,2026年华为在中国AI加速器市场的份额将跃升至50%,而英伟达受制裁影响或将大幅缩水至8%。
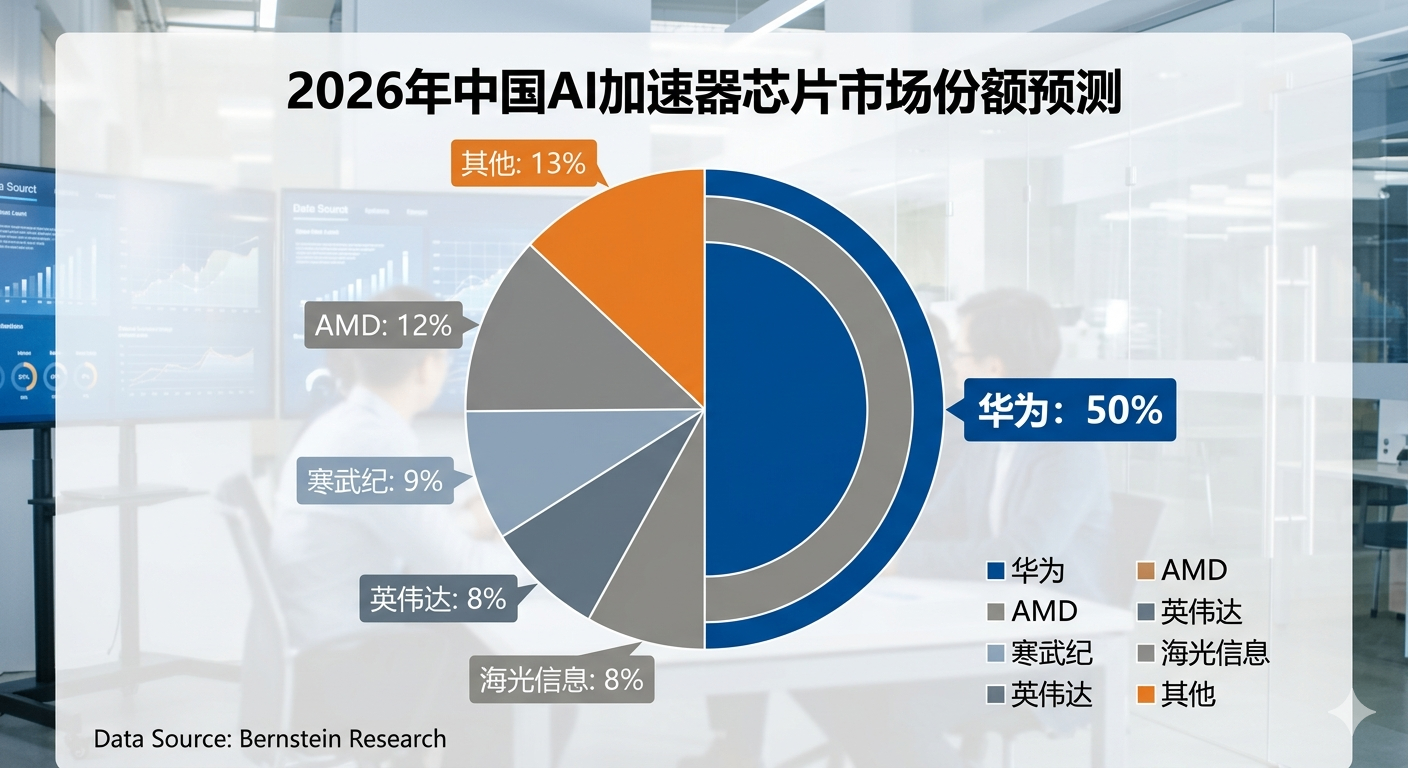
图表深度解读:华为市场份额的绝对反超与英伟达的衰退,标志着国内AI基建正式完成硬脱钩,国产算力迎来规模化红利。
二、 宏观约束下的算力与电力博弈
随着大模型参数突破万亿规模,AI产业的竞争正从单纯的"算法战"向"能源战"蔓延。
1. 数据中心的"电老虎"效应
国家发改委数据显示,2025年全国全社会用电量首超10万亿千瓦时,其中算力核心枢纽贵安新区(华为云数据中心所在地)用电量增速高达56.92%。此外,《人民日报》引用的宏观预测指出,到2030年,我国数据中心能耗总量将超4000亿千瓦时。 庞大的电力消耗正在成为制约超大模型常态化部署的核心宏观约束。
2. 算法层面的能耗优化破局
面对算力与电力的双重瓶颈,DeepSeek在模型架构上做出了极具针对性的妥协与创新。官方技术文档显示,DeepSeek-V4开创了Token维度的压缩机制,并深度结合DSA稀疏注意力(DeepSeek Sparse Attention),大幅降低了计算峰值与显存需求。
国务院发展研究中心宏观经济研究员推测,未来大模型的商业护城河将从"总参数量"转向"单位能耗算力产出比(Performance per Watt)"。 能够将绿色算力调度与底层算法降耗深度融合的企业,才能在国家"双碳"目标下获得更长的生存周期。
三、 Token定价逻辑与下半年价格走势预测
DeepSeek历来被称为大模型界的"价格屠夫",但此次V4版本的定价策略不仅是商业竞争手段,更是国产算力成本优势的直接外溢。
1. 当前API定价体系的成本解构
| 模型版本 | 输入单价(缓存命中/百万Tokens) | 输出单价(百万Tokens) |
|---|---|---|
| DeepSeek-V4-Flash | 0.2元 | 2.0元 |
| DeepSeek-V4-Pro | 1.0元 | 24.0元 |
数据来源:DeepSeek官方公告,2026年4月
2. 华为新节点上市与下半年降价预期
尽管目前API定价已极具竞争力,但官方披露目前DS-V4-Pro的高端服务吞吐量仍受限于当前集群规模。观察者网报道明确指出,预计今年下半年华为昇腾950超节点批量上市后,Pro版本的API价格将迎来大幅下跌。
Gartner机构分析师据此预测,随着下半年国产大算力集群(超节点)完成规模化部署,硬件摊销与互联折损成本将呈指数级下降。分析显示,至2026年四季度,国内头部万亿大模型的推理Token成本有望再度下探30%至50%,全面加速通用人工智能在政务、金融等高价值行业的下沉普及。





