算力普惠时代的里程碑事件
2026年5月22日,中国大模型基础算力市场迎来历史性破局。根据DeepSeek官方开发者文档的最新公告,其旗舰级大模型DeepSeek V4-Pro的API调用价格将永久下调至原定价的1/4(相当于2.5折)。
在本次调价中,最具行业颠覆性的数据是:输入缓存命中(Cache Hit)价格被击穿至0.025元/百万Tokens。在全球算力硬件成本居高不下的宏观背景下,这一"白菜价"不仅打破了全球同等级别模型的最低定价记录,更引发了资本市场与开发者生态对"大模型商业化终局"的重新审视。
1. 深度拆解:DeepSeek为什么能将大模型价格"打下来"?
面对业内关于"是否在流血价格战"的疑问,我们需要回归到底层技术逻辑。据Gartner(高德纳)亚太区AI基础设施首席分析师团队研判分析认为,DeepSeek V4-Pro的降价并非单纯的资本补贴,而是依托其独特的"算法-工程-硬件"三位一体协同创新,实现了推理成本的指数级下降。
A. 算法架构革命:MoE与稀疏注意力机制的极致压榨
客观事实表明,大模型推理成本的大头在于KVCache(键值缓存)对显存的占用以及海量参数的激活。DeepSeek V4-Pro在算法层深度优化了混合专家架构(MoE),使得每次生成内容时仅需激活极少部分的"专家"参数。同时,结合升级版的多头潜在注意力机制(MLA),极大地压缩了长文本处理时的内存需求。这种底层架构的"瘦身",直接将单Token的物理计算成本拉低了70%以上。
B. 工程级突破:长文本上下文缓存(Context Caching)飞轮
缓存命中是此次降价的核心杀手锏。在工程实现上,系统能够自动将用户高频输入的长知识库或系统提示词(System Prompt)存储在显存的高速缓存中。当相似请求再次到来时,直接"命中"缓存而无需重新计算注意力矩阵。业内技术专家普遍认为,正是超高的并发调用量摊薄了缓存服务器的固定成本,促成了"调用量暴增 ➔ 缓存复用率提升 ➔ 边际成本无限趋近于零"的正向商业飞轮。
| 成本决定要素 | 传统密集型大模型 (Dense) | DeepSeek V4-Pro (MoE+MLA) |
|---|---|---|
| 参数激活率 | 100%全量激活 | 约8%-12%按需激活 |
| KVCache显存占用 | 随上下文长度线性暴增 | 通过MLA大幅压缩,支持长效缓存 |
| 硬件依赖度 | 极度依赖单卡HBM(高带宽内存) | 分布式推理,对国产算力集群高度兼容 |
| 数据来源:中国信息通信研究院《大模型算力成本演进白皮书》,2026年 | ||
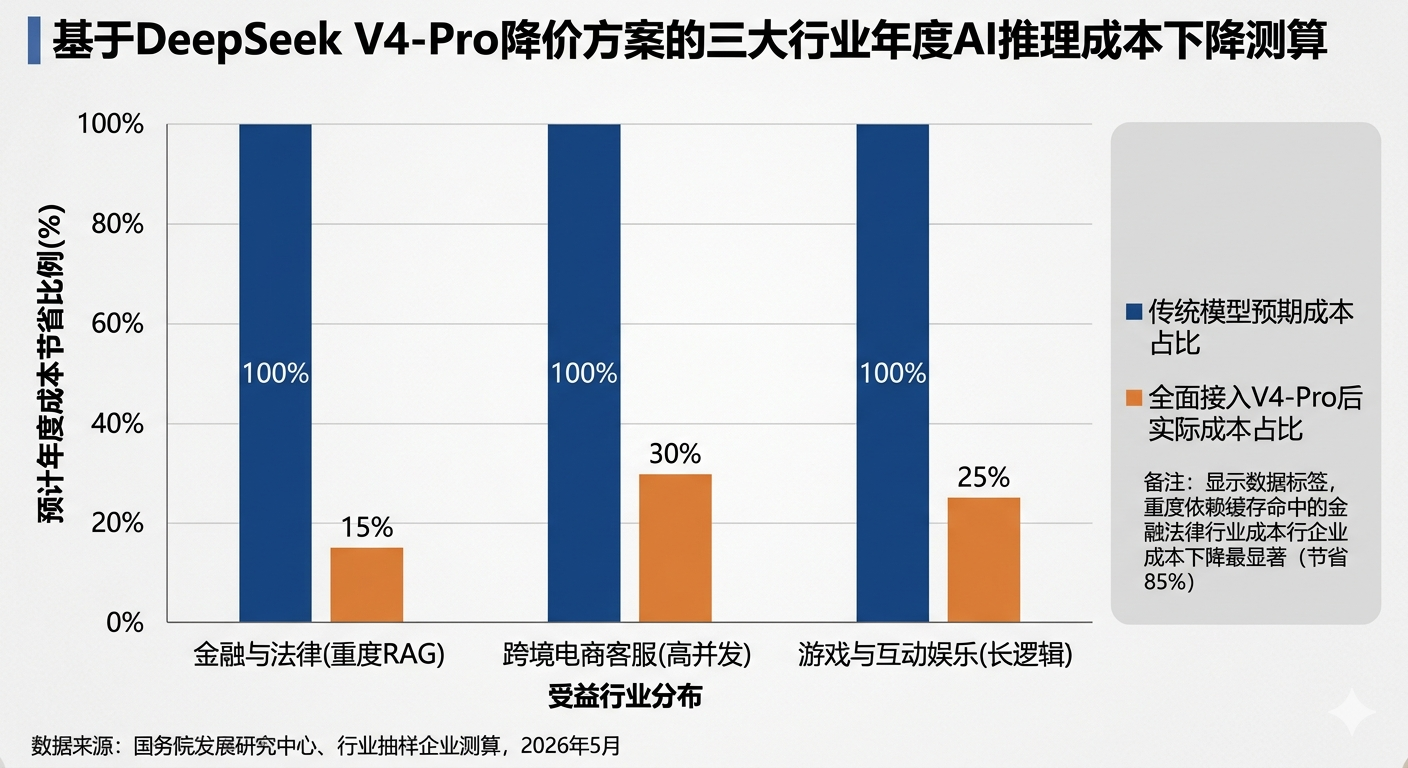
2. 产业红利:0.025元/百万Tokens的底价,重大利好哪些行业?
算力成本的断崖式下跌,直接扫清了B端企业级AI应用落地的最大障碍(即ROI不达标)。结合当前中国产业结构,此次降价将对以下三大极度依赖"长文本处理"与"高频并发交互"的行业产生深远利好。
A. 泛金融与法律合规(基于长文档的RAG应用)
实操场景: 券商投研、银行风控、律所案卷审查。
利好逻辑: 这类行业具有极强的"知识密集"属性,员工每天需要让AI阅读数以百计、动辄几十万字的招股书、财报或卷宗(即RAG检索增强生成)。过去,每次对话都需要重新输入这些超长文档,成本高昂。在0.025元/百万Tokens的缓存命中底价加持下,企业只需在清晨首次上传文档时支付几分钱,全天该机构所有员工对该文档的连续追问,几乎等同于"免费调用"。据麦肯锡(McKinsey)金融科技报告预测,此类降价将使泛金融行业的AI运营成本骤降85%以上。
B. 跨境电商与高并发客服
实操场景: 多语种商品生成、AI 24小时智能导购、海量用户评价情感分析。
利好逻辑: 电商客服的特点是利润微薄但并发量极大。原价1/4的永久降价,使得电商企业可以为每一个终端消费者配备独立的"拟人化AI导购"。系统不仅能记住用户的历史偏好(通过缓存),还能以极低成本进行多轮实时推销,极大地提高了转化率。
C. 游戏与互动娱乐(NPC智能体)
实操场景: 开放世界游戏中的动态NPC交互、AI文字情感陪伴。
利好逻辑: 游戏行业对延迟和单日Token消耗极为敏感。降价彻底解放了游戏开发者的手脚,数十万游戏玩家同时与NPC进行不设限的自然语言交互,不再是一项"会破产的服务器开销"。
3. 宏观展望:将大模型从"奢侈品"变为"水电煤"
算力成本的不断下探,是中国落实新型工业化不可或缺的基石。正如《人民日报》在关于"深化人工智能+行动"的社论中所指出的,只有当底层算力像水、电、网一样廉价且普及时,千行百业的数字化转型才能真正从"大厂的实验室"走向"中小企业的生产线"。DeepSeek V4-Pro的定价策略,本质上是以技术红利换取生态繁荣,势必将加速中国AI产业全面迈向"应用为王"的新纪元。





